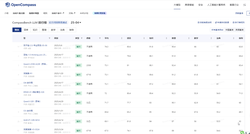
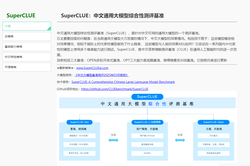
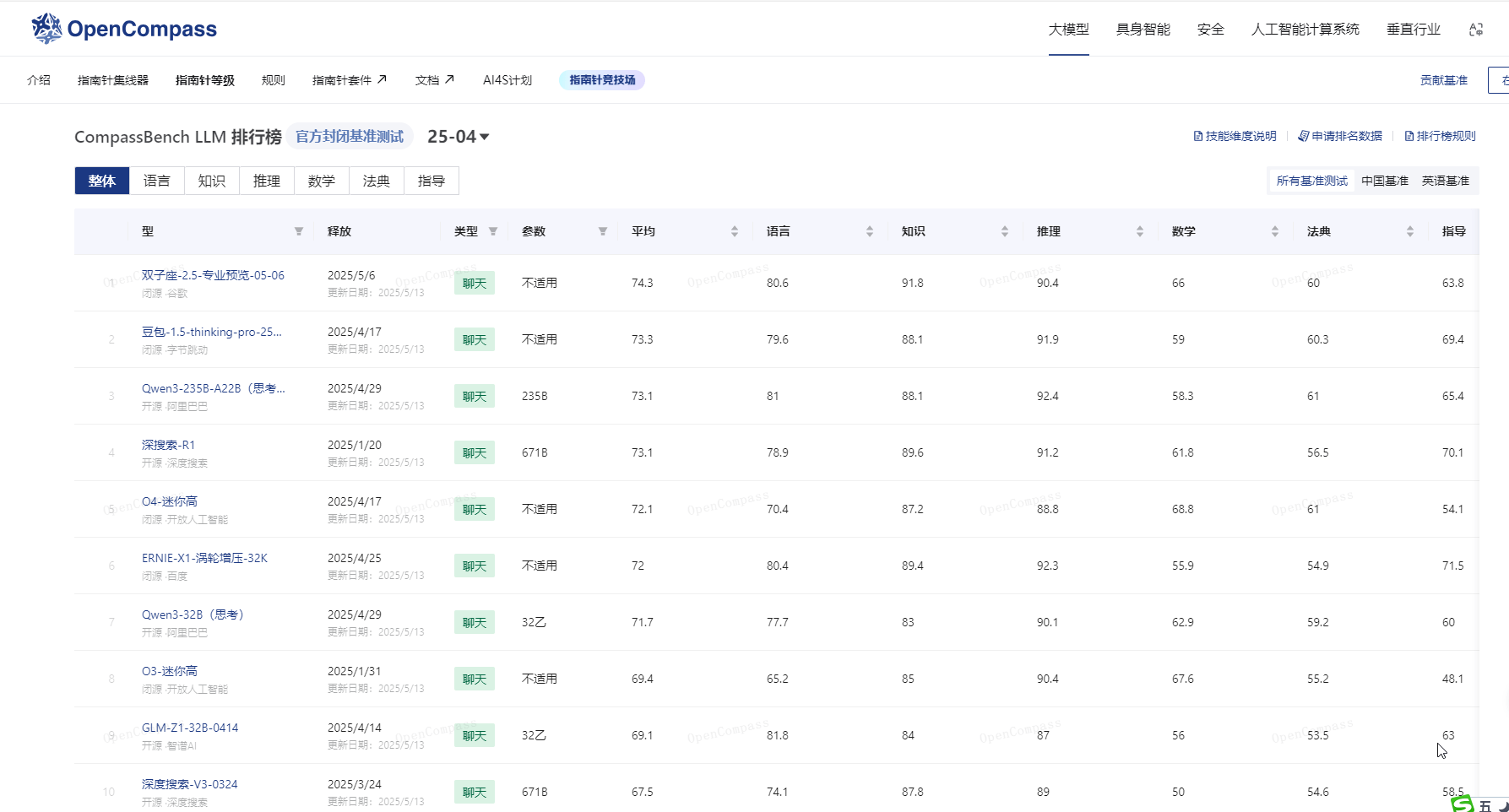
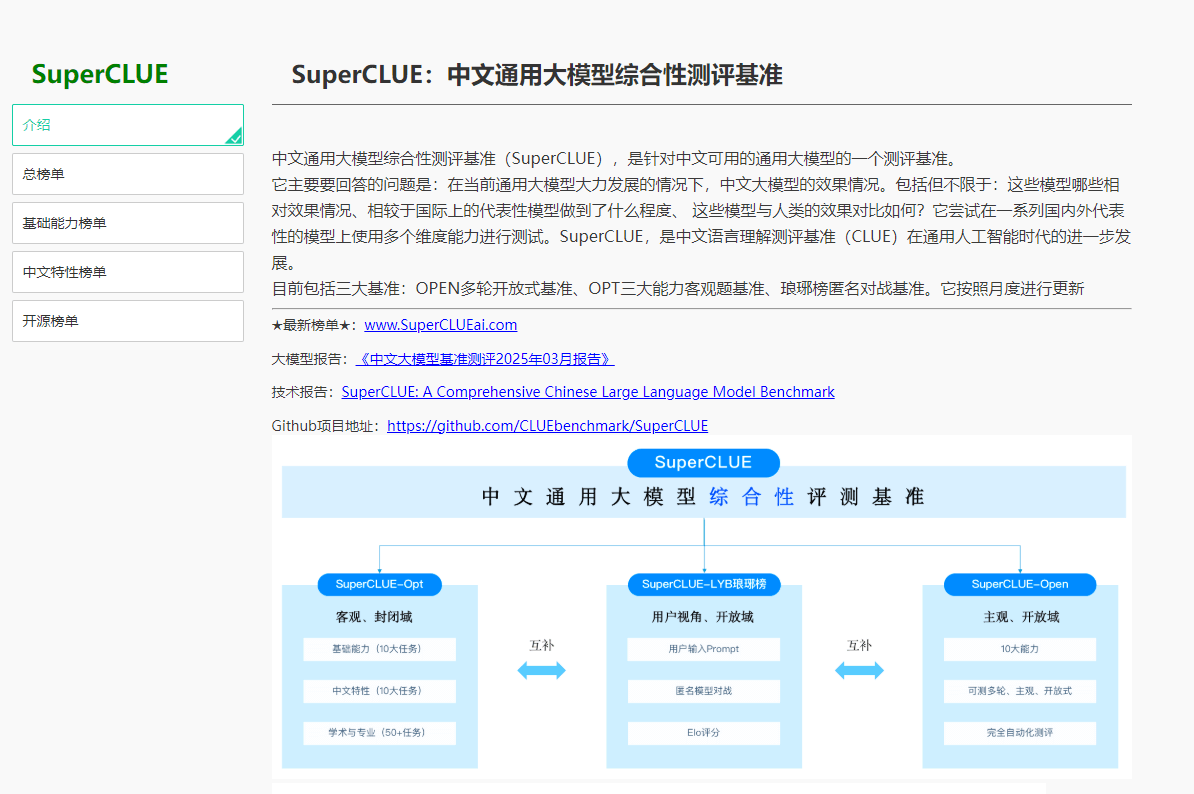
C-Eval是适用于大语言模型的多层次多学科中文评估套件,由上海交通大学、清华大学和爱丁堡大学研究人员在2023年5月份联合推出,包含13948个多项选择题,涵盖52个不同的学科和四个难度级别,用在评测大模型中文理解能力。通过零样本(zero-shot)和少样本(few-shot)测试,C-Eval 能评估模型在未见过的任务上的适应性和泛化能力。
C-Eval 介绍
特别声明
本站13dh.com提供的C-Eval来源于网络,本站不保证第三方网页的链接的安全性、正确性、及时性、合法性、准确性和完整性,您可能从该第三方网页上获得资讯及享用服务,13dh.com及其所有者对其合法性概不负责,亦不承担任何法律责任。同时,对于该外部链接的指向,不由13dh.com实际控制,13dh.com收录时,该网页上的内容,都属于合规合法,后期网页的内容如出现违规,请你点此留言或发邮件到551717082@qq.com联系网站管理员进行删除,本站及本站所有者对其概不负责,亦不承担任何法律责任。
-
PDF 处理能手
smallPDF: https://smallpdf.com/ Online OCR: https://www.onlineocr.net/ PDF to Word Converter: https://www.pdftoword.com/ 加加PDF: https://www.addpdf.cn/pdf-to-word ilovePDF: https://www.ilovepdf.com/ -
红警网站合集
https://www.ra2web.com/ -
视频图片文档处理网站
1.图像修复:https://zh.pixfix.com/ 2.All to all(格式转换):https://www.alltoall.net/ 3.Extract Bg:一个简单而免费的工具,可以从任何图像中去除背景。网址:一https://www.erase.bg/ 4.图片去水印:https://zh-cn.aiseesoft.com/watermark-remover-online/ -
游戏资源宝库
游侠网单机游戏: https://www.ali213.net/ 3DM单机游戏: https://www.3dmgame.com/ 游民星空单机游戏: https://down.gamersky.com/ 小霸王游戏: https://www.yikm.net/ 乐猪游戏: https://www.lezhugame
AI模型评测